
Table of Contents
- Table of Contents
- Overview
- Machine Learning Team
- Biomechanics Team
- Development Team
- Conclusion and Next Steps
Overview
My last semester at Georgia Tech marked over three years of working at EPIC Lab on the knee-ankle prosthesis project. With several other projects, including capstone, and graduation all occurring together, it was perhaps not my most impactful semester at EPIC, but our team made significant progress, particularly on our adaptive machine learning pipeline. This post builds directly off of previous posts (Semesters 3, 4, 5, 6, and 7), which may introduce vocabulary or topics relevant to this post. As usual, because of the sensitive nature of active research which is not entirely mine, I can only give overviews here, and will not be sharing any results or code unless the lab has published a paper or open-sourced a codebase.
Machine Learning Team
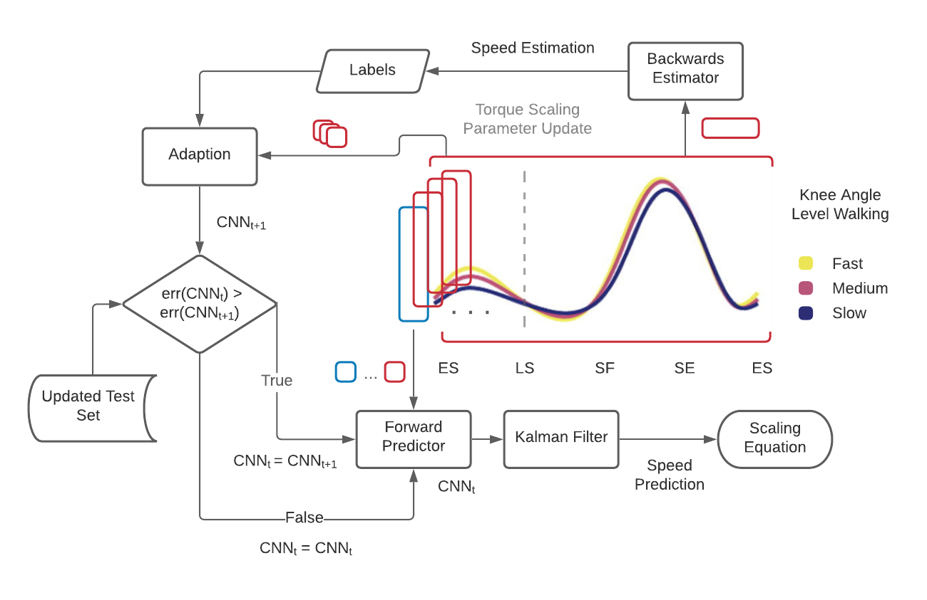
The machine learning team focused this semester on the adaptive pipeline. The adaptive pipeline aims to improve the performance of subject independent environmental parameter estimators by further training the models on data collected while the leg is used. An outline of the adaptive pipeline is pictured above. Data is collected in real-time by the prosthetic leg, which is labeled by a ‘Backwards Estimator’ for classification tasks, such as intent recognition, or an ‘A-causal Estimator’ for regression tasks, such as speed estimation. In most cases, the backwards estimation task (for instance, classifying the previous stride’s mode) is much easier than the forwards estimation task (classifying the intent of the next stride, in the future). Similarly, a-causal estimation of speed or slope, which can use time points in future to determine speed retroactively, is an easier problem than causal estimation, which occurs in real time and has no access to future information. Because of this, backwards and a-causal estimators can typically be created with higher accuracies than the corresponding forwards and causal estimators. This accuracy differential drives training of the independent model in the adaptation step. In this step, data labeled by the backwards or a-causal estimators is used to train the forwards or causal estimators, with subject-dependent data. Over time, the accuracy of these models can be improved by the adaptation step. As the models are improved, their accuracy on a validation set is checked to avoid over-fitting. As the model is improved, it replaces previous models, and the improved model is continued to be used for real-time control of the prosthesis.
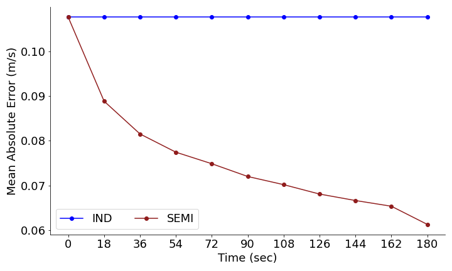
The plot above shows an offline demonstration of how incorporating subject-dependent data can improve an initially subject independent model. This used the real ground truth as the adaptive pipeline label, and therefore shows a best-case scenario where the a-causal estimator is perfect.
This semester, the primary tasks undertaken were the design and testing of the backwards and a-causal estimators. I had tackled forwards and backwards estimators in previous semesters, typically finding decent success with applications of XGBoost and Linear models (see Semesters X and X). Speed estimation was tackled by Jairo, our graduate student mentor; slope estimation was tackled by Jeongwoo Cho; and mode estimation by Helen Yoo. I worked on the implementation of the adaptive pipeline in the prosthesis firmware. Each of these projects reached varying levels of success; next semester will begin the real-time testing of this pipeline on the prosthesis.
Biomechanics Team
 The biomechanics team, which I have grown increasingly distant from as my focus has become more heavily involved in machine learning, began a new study this semester; they are running a large-scale comparison between three commercially available microprocessor knees (MPKs): the Rheo Knee (semi-active), the C-Leg (semi-active) and the Power Knee (active). Each subject wears the MPK outside of the lab for a period to adjust to it, after which they perform several trials of ramps, stairs, and balance beam walking. Each trial is captured via Vicon Motion Cameras, and joint kinematics, dynamics, and powers are computing using OpenSim. N=4 subjects were collected and processed by the biomechanics team this semester, and will be continued over the summer.
The biomechanics team, which I have grown increasingly distant from as my focus has become more heavily involved in machine learning, began a new study this semester; they are running a large-scale comparison between three commercially available microprocessor knees (MPKs): the Rheo Knee (semi-active), the C-Leg (semi-active) and the Power Knee (active). Each subject wears the MPK outside of the lab for a period to adjust to it, after which they perform several trials of ramps, stairs, and balance beam walking. Each trial is captured via Vicon Motion Cameras, and joint kinematics, dynamics, and powers are computing using OpenSim. N=4 subjects were collected and processed by the biomechanics team this semester, and will be continued over the summer.
Development Team
 The development team undertook several quality-of-life updates for our experimental pipeline and the device, including manufacturing several adjustable and custom pylons for adjusting the height of the prosthesis, designing and manufacturing several electronics cases and fixture structures, and creating a subject orientation powerpoint which lays out what to expect during an experiment for new subjects. While not crucial research pieces, these improvements help make experiments run faster and safer, and are key to keeping the team moving consistently forwards.
The development team undertook several quality-of-life updates for our experimental pipeline and the device, including manufacturing several adjustable and custom pylons for adjusting the height of the prosthesis, designing and manufacturing several electronics cases and fixture structures, and creating a subject orientation powerpoint which lays out what to expect during an experiment for new subjects. While not crucial research pieces, these improvements help make experiments run faster and safer, and are key to keeping the team moving consistently forwards.
Conclusion and Next Steps
The summer and next semester will see significant work pushing towards papers on both the adaptive and MPK studies. I will continue to be associated with the adaptive development to some extent, but will likely not continue working with the biomechanics team following my graduation. Most importantly, I will be working on my first lead-author paper from the lab, concerned with improving the accuracy of machine learning state estimation with deeper subject-independent models, to provide improvements over XGBoost and Linear models which we currently use. These models will likely be directly incorporated into the adaptive pipeline, as more accurate baseline models will improve the efficacy of that pipeline overall.